
GroupBy(), Continued
As we learned last lecture, a groupby operation involves some combination of splitting a DataFrame into grouped subframes, applying a function, and combining the results.
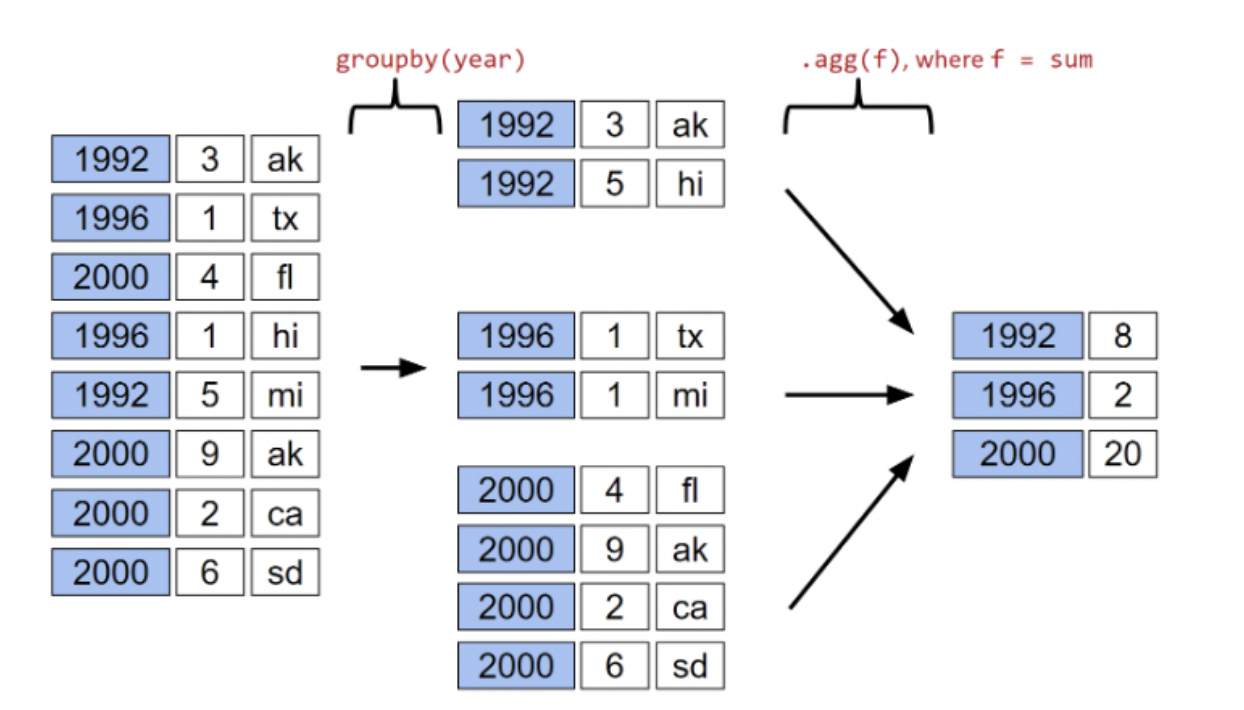
- Organizes all rows with the same year into a subframe for that year.
- Creates a new DataFrmae with one row representing each subframe year.
- Combines all integer rows in each subframe using the sum function.
Aggregation with lambda functions
# naive approach group by the Party column and aggregate by the maximum
elections.groupby("Party").agg(max).head(10)
# Notice: This is wrong approach!
'''
Different approach
1. Sorth the DataFrame so that rows are in descending order of %
2. Group by Party and select the first row or each groupby object
The first row of each groupby object will contain information about the Candidate
with the higher voter %
'''
elections_sorted_by_percent = elections.sort_values("%", ascending=False)
elections_sorted_by_percent.head(5)elections_sorted_by_percent.groupby("Party").agg(lambda x : x.iloc[0]).head(10)
# Equivalent to the below code
# elections_sorted_by_percent.groupby("Party").agg('first').head(10)# Using the idxmax function
best_per_party = elections.loc[elections.groupby('Party')['%'].idxmax()]
best_per_party.head(5)# Using the .drop_duplicates function
best_per_party2 = elections.sort_values('%').drop_duplicates(['Party'], keep='last')
best_per_party2.head(5)
Other GroupBy Features
- .max: creates a new DataFrame with the maximum value of each group
- .mean: creates a new DataFrame with the mean value of each group
- .size: creates a new Series with the number of entries in each group
The following are equivalent:
- elections.groupby("Candidate").agg(mean)
- elections.groupby("Candidate").mean()
groupby.filter()
'''
For each yaer, find the maximum % among all rows for that year
If maximum % is lower than 45%, we will tell pandas to keep
all rows corressponding to that year
'''
elections.groupby("Year").filter(lambda sf: sf["%"].max() < 45).head(9)We difined our filtering function "f" to be lambda sf: sf["%"].max() < 45.
The filtering function will find the maximum "%" value among all entries in the grouped subframe, which we call sf
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Joining Tables (0) | 2023.05.23 |
|---|---|
| Aggregation Data with Pivot Table in Pandas (0) | 2023.05.23 |
| Aggregating Data with GroupBy in Pandas (0) | 2023.05.23 |
| Add & Remove Columns (0) | 2023.05.23 |
| Handy Utility Functions in Pandas (0) | 2023.05.23 |