
# check out the first three lines:
with open("data/cdc_tuberculosis.csv", "r") as f:
i = 0
for row in f:
print(row)
i += 1
if i > 3:
break
※ Python's print() prints each string (including the newline), and an additional newline on top of that.
# We can use the repr() function to return the raw sting with all special characters
with open("data/cdc_tuberculosis.csv", "r") as f:
i = 0
for row in f:
print(repr(row)) # print raw strings
i += 1
if i > 3:
break
# can cause wrangle the data. need to clean the data
# can cause "Unnamed" column names
tb_df = pd.read_csv("data/cdc_tuberculosis.csv")
tb_df.head()
# identify the row with the right header.
tb_df = pd.read_csv("data/cdc_tuberculosis.csv", header=1) # row index
tb_df.head(5)The second result shows:
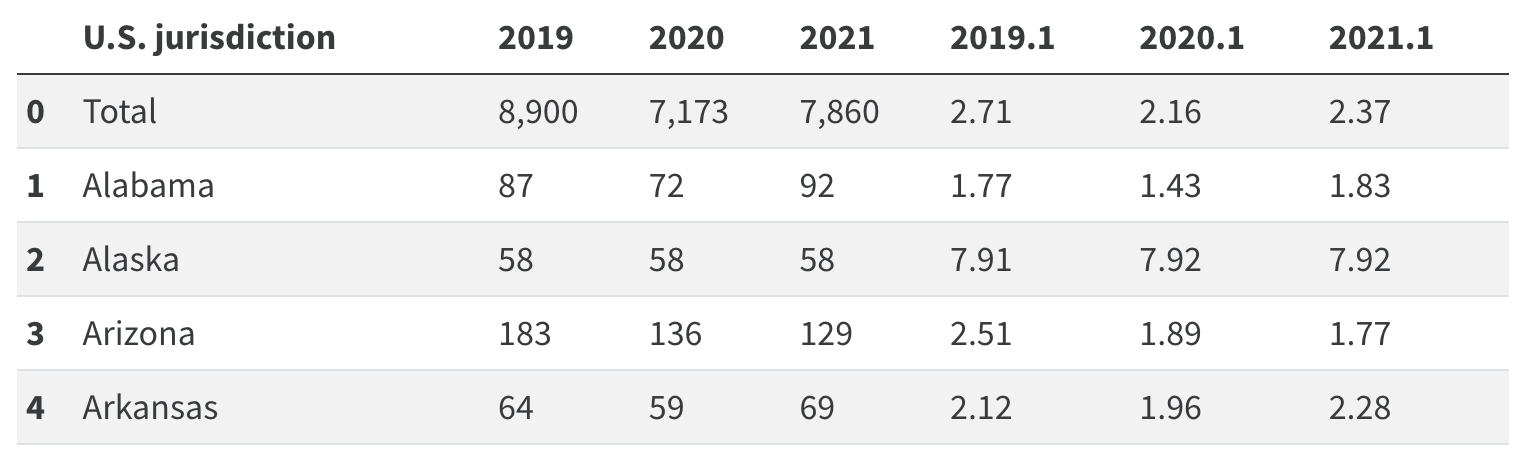
However, we can't differenciate between the "Number of TB cases" and "TB incidence" year column.
# We can do this manually with df.rename()
rename_dict = {'2019': 'TB cases 2019',
'2020': 'TB cases 2020',
'2021': 'TB cases 2021',
'2019.1': 'TB incidence 2019',
'2020.1': 'TB incidence 2020',
'2021.1': 'TB incidence 2021'}
tb_df = tb_df.rename(columns=rename_dict)
tb_df.head(5)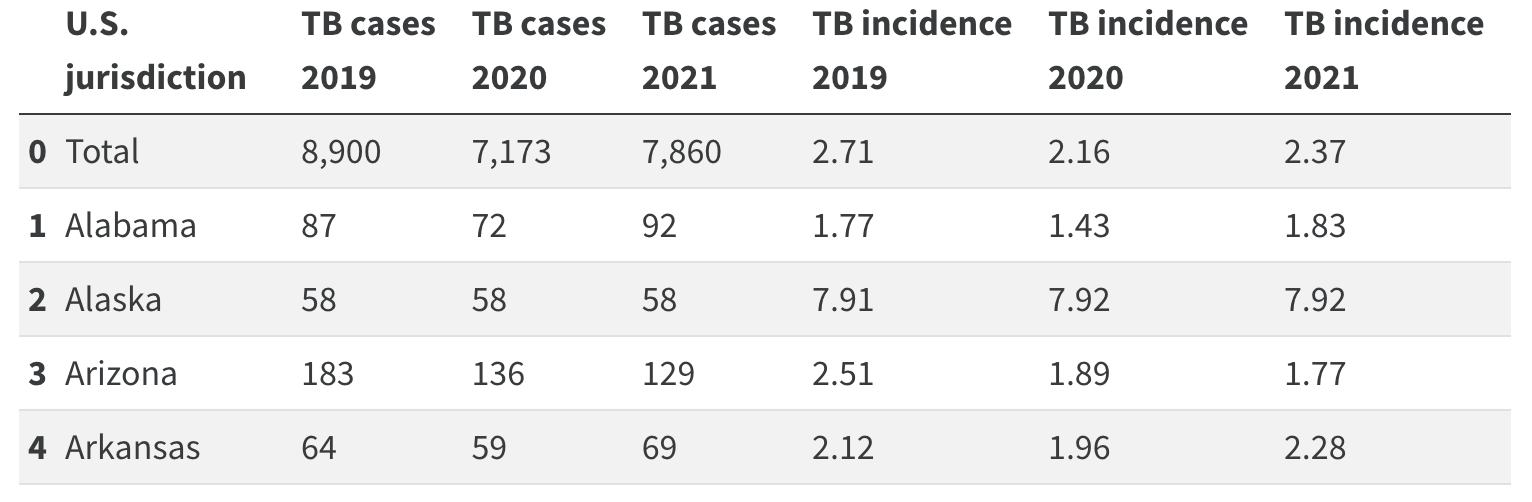
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Gather more data & join data on primary keys (0) | 2023.05.24 |
|---|---|
| Record Granularity (0) | 2023.05.24 |
| Data Cleaning Structure (0) | 2023.05.24 |
| Joining Tables (0) | 2023.05.23 |
| Aggregation Data with Pivot Table in Pandas (0) | 2023.05.23 |
# check out the first three lines:
with open("data/cdc_tuberculosis.csv", "r") as f:
i = 0
for row in f:
print(row)
i += 1
if i > 3:
break※ Python's print() prints each string (including the newline), and an additional newline on top of that.
# We can use the repr() function to return the raw sting with all special characters
with open("data/cdc_tuberculosis.csv", "r") as f:
i = 0
for row in f:
print(repr(row)) # print raw strings
i += 1
if i > 3:
break
# can cause wrangle the data. need to clean the data
# can cause "Unnamed" column names
tb_df = pd.read_csv("data/cdc_tuberculosis.csv")
tb_df.head()
# identify the row with the right header.
tb_df = pd.read_csv("data/cdc_tuberculosis.csv", header=1) # row index
tb_df.head(5)The second result shows:
However, we can't differenciate between the "Number of TB cases" and "TB incidence" year column.
# We can do this manually with df.rename()
rename_dict = {'2019': 'TB cases 2019',
'2020': 'TB cases 2020',
'2021': 'TB cases 2021',
'2019.1': 'TB incidence 2019',
'2020.1': 'TB incidence 2020',
'2021.1': 'TB incidence 2021'}
tb_df = tb_df.rename(columns=rename_dict)
tb_df.head(5)
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Gather more data & join data on primary keys (0) | 2023.05.24 |
|---|---|
| Record Granularity (0) | 2023.05.24 |
| Data Cleaning Structure (0) | 2023.05.24 |
| Joining Tables (0) | 2023.05.23 |
| Aggregation Data with Pivot Table in Pandas (0) | 2023.05.23 |