
Data Cleaning(Data Wrangling)
Data Cleaning is the process of transforming raw data to facilitate subsequent analysis.
It is used to like:
- Unclear structure or formatting
- Missing or corrupted values
- Unit Conversions
Exploratory Data Analysis (EDA)
EDA is the process of understanding a new dataset. It is an open- ended, informational analysis that involves familiarizing ourselves with the variables present in the data, discovering potential hypotheses, and identifying potential issues with the data.
Structure
File Format
import pandas as pd
pd.read_csv("data/elections.csv").head(5)CSV: Comma-Seperated Values

Each row(record) is delimited by a newline.
Each column(field) is delimited by a comma.
TSV: Tab-Seperated Values

In a TSV, records are still delimited by a newline, while fileds are delimited by \t tab character.
A TSV can be loaded into pandas using pd.read_csv() with the delimiter parameter: pd.read_csv("file_name.tsv", delimiter="\t").
Json (JavaScript Object Notation)

JSON files behave similarly to Python dictionaries. They can be loaded into pandas using pd.read_json.
Variable Types
1. Quantitative variables
- Continouous quantitative variables: numeric data that can be measured on a continuous scale to arbitary precision. Continuous variables do not have a strict set of possible values - they can be recorded to any number of decimal places. For example, weights, GPA, or CO2 concentrations
- Discrete quantitative variables: numeric data that can only take on a finite set of possible values. For example, someone's age or number of siblings.
2. Qualitative variables(Categorical variables)
- Ordinal qualitative variables: categories with ordered levels. Specifically, ordinal variables are those where the difference between levels has no consistent, quantifiable meaning. For example, a Yelp rating or set of income brackets.
- Nominal qualitative variables: categories with no specific order. For example, someone's political affiliation or Cal ID number.
Primary and Foreign Keys
Using a "key" determine what rows should be merged from each table.
The primary key is the column or set of columns in a table that determine the values of the remaining columns.
It can be thought as the unique identifier for each individual row in the table.
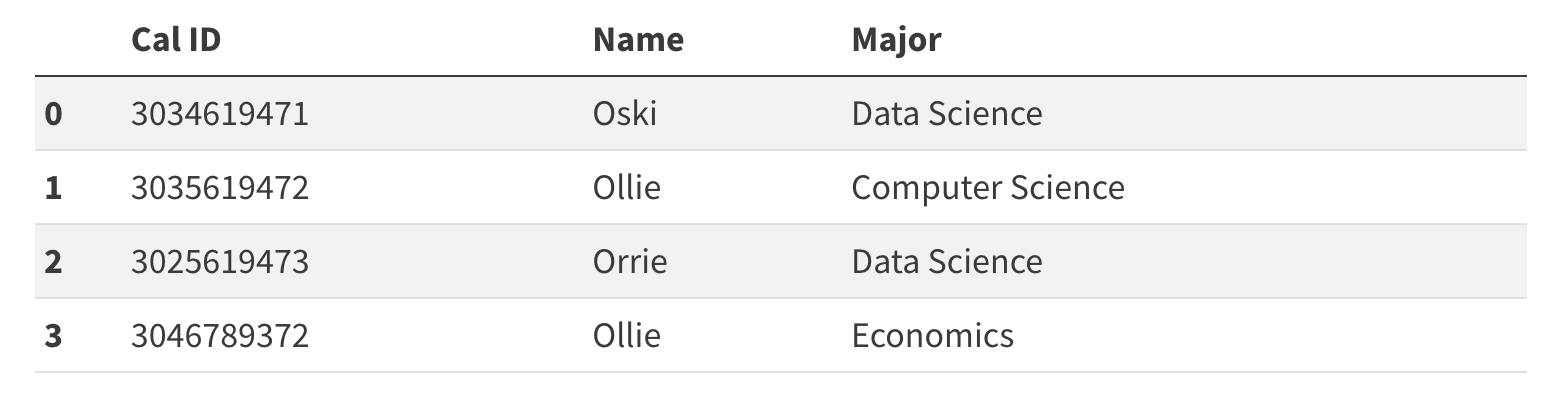
In this case, Cal ID might be used as the primary key.
The foreign key is the column or set of columns in a table that reference primary keys in other tables.
Knowing a dataset's foreign keys can be useful when assigning the left_on and right_on parameteres of .merge.
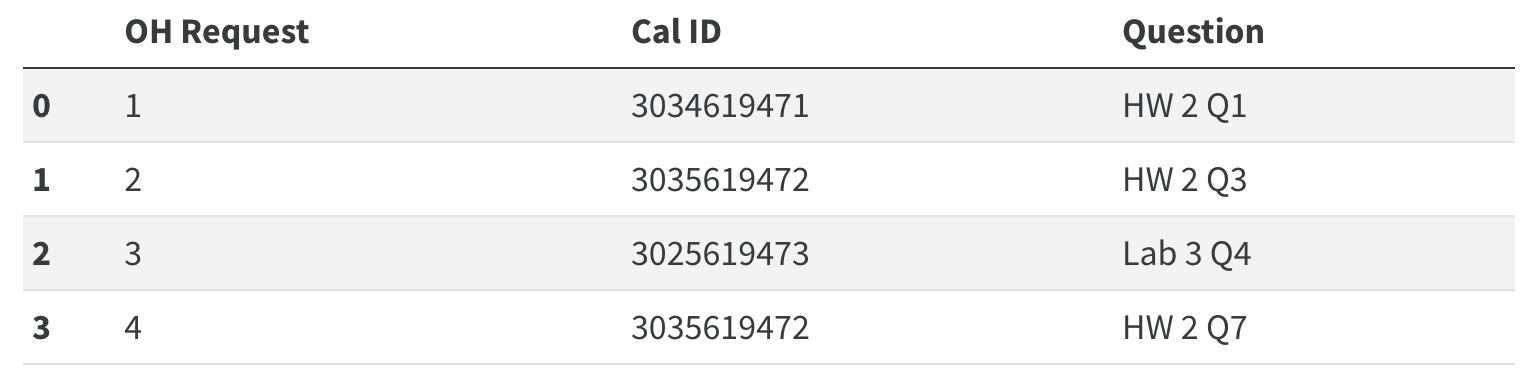
"Cal ID" is a foreign key referencing the previous table.
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Record Granularity (0) | 2023.05.24 |
|---|---|
| CSV files and field names (0) | 2023.05.24 |
| Joining Tables (0) | 2023.05.23 |
| Aggregation Data with Pivot Table in Pandas (0) | 2023.05.23 |
| Aggregation in Pandas (0) | 2023.05.23 |
Data Cleaning(Data Wrangling)
Data Cleaning is the process of transforming raw data to facilitate subsequent analysis.
It is used to like:
- Unclear structure or formatting
- Missing or corrupted values
- Unit Conversions
Exploratory Data Analysis (EDA)
EDA is the process of understanding a new dataset. It is an open- ended, informational analysis that involves familiarizing ourselves with the variables present in the data, discovering potential hypotheses, and identifying potential issues with the data.
Structure
File Format
import pandas as pd
pd.read_csv("data/elections.csv").head(5)CSV: Comma-Seperated Values
Each row(record) is delimited by a newline.
Each column(field) is delimited by a comma.
TSV: Tab-Seperated Values
In a TSV, records are still delimited by a newline, while fileds are delimited by \t tab character.
A TSV can be loaded into pandas using pd.read_csv() with the delimiter parameter: pd.read_csv("file_name.tsv", delimiter="\t").
Json (JavaScript Object Notation)
JSON files behave similarly to Python dictionaries. They can be loaded into pandas using pd.read_json.
Variable Types
1. Quantitative variables
- Continouous quantitative variables: numeric data that can be measured on a continuous scale to arbitary precision. Continuous variables do not have a strict set of possible values - they can be recorded to any number of decimal places. For example, weights, GPA, or CO2 concentrations
- Discrete quantitative variables: numeric data that can only take on a finite set of possible values. For example, someone's age or number of siblings.
2. Qualitative variables(Categorical variables)
- Ordinal qualitative variables: categories with ordered levels. Specifically, ordinal variables are those where the difference between levels has no consistent, quantifiable meaning. For example, a Yelp rating or set of income brackets.
- Nominal qualitative variables: categories with no specific order. For example, someone's political affiliation or Cal ID number.
Primary and Foreign Keys
Using a "key" determine what rows should be merged from each table.
The primary key is the column or set of columns in a table that determine the values of the remaining columns.
It can be thought as the unique identifier for each individual row in the table.
In this case, Cal ID might be used as the primary key.
The foreign key is the column or set of columns in a table that reference primary keys in other tables.
Knowing a dataset's foreign keys can be useful when assigning the left_on and right_on parameteres of .merge.
"Cal ID" is a foreign key referencing the previous table.
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Record Granularity (0) | 2023.05.24 |
|---|---|
| CSV files and field names (0) | 2023.05.24 |
| Joining Tables (0) | 2023.05.23 |
| Aggregation Data with Pivot Table in Pandas (0) | 2023.05.23 |
| Aggregation in Pandas (0) | 2023.05.23 |