
Text Fields and Data Cleaning / EDA
Extract quantitative values from text: dates, times, positions, etc.
Determine if missing values are denoted

# split
time_str = first.split('[')[1].split(' ', 1)[0] # '26/Jan/2014:10:47:58'
day, month, rest = time_str.split('/') # ['26', 'Jan', '2014:10:47:58']
year, hour, minute, second = rest.split(':') # ['2014', '10', '47', '58']
year, month, day, hour, minute, secondRegular Expressions
import re
pattern = r'(\d+)(\w+)(\d+):(\d+):(\d+):(\d+)'
re.search(pattern, first).groups()
# ('26', 'Jan', '2014', '10', '47', '58')
# = r'(..)/(...)/(....):(..):(..):(..)'Example:

3 of any digit, then a dash, then 2 of any digit, then a dash, then 4 of any digit
text = "My social security number is 123-45-6789.";
pattern = "[0-9]{3}-[0-9]{2}-[0-9]{4}"
re.findall(pattern, text)
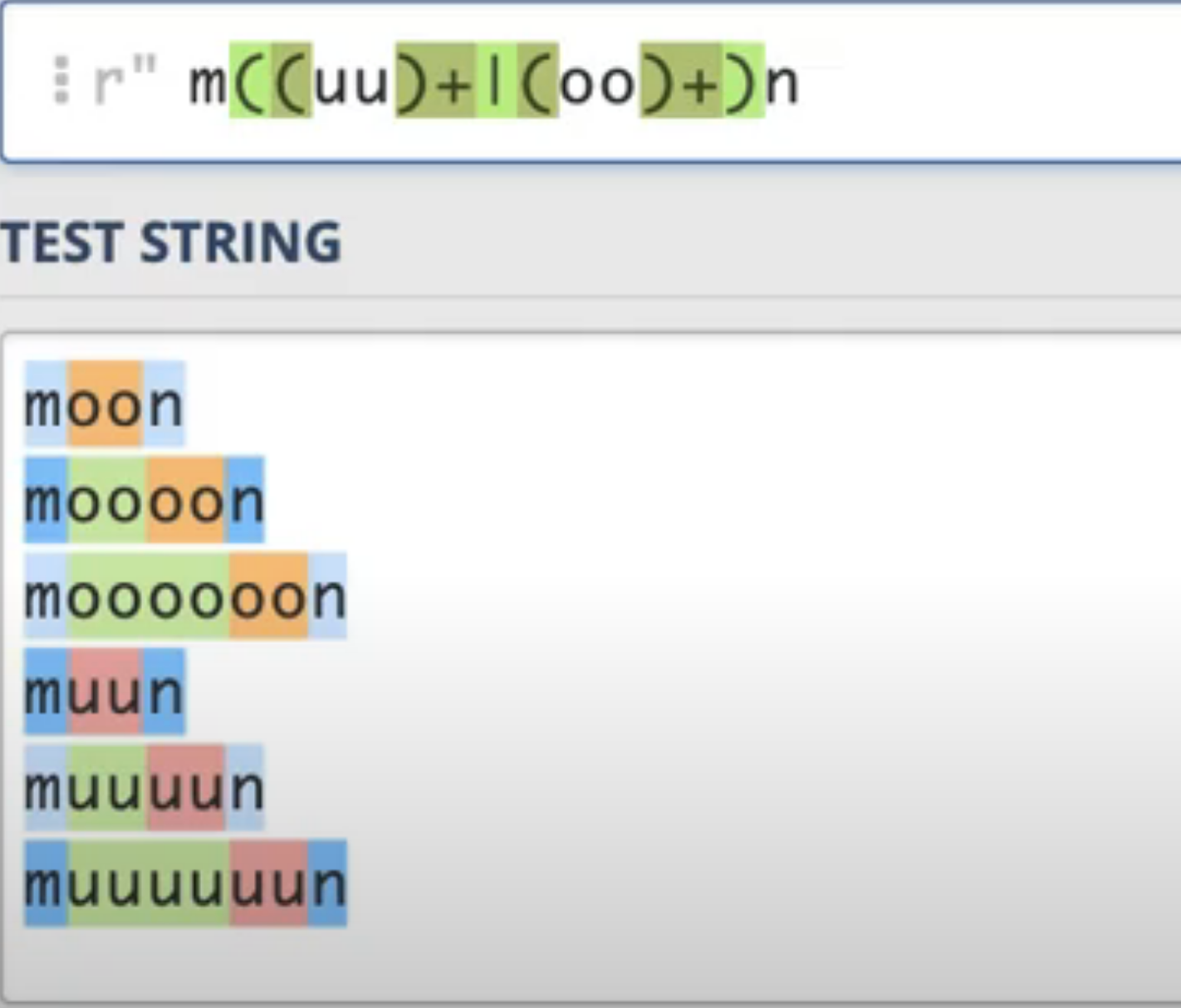
Example:
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Foundation of Machine Learning (0) | 2023.05.31 |
|---|---|
| SQL in Pandas Review (0) | 2023.05.30 |
| EDA Review (0) | 2023.05.30 |
| Data Cleaning Review (0) | 2023.05.28 |
| Pandas part 2 Review (0) | 2023.05.27 |