
Modeling
Making Predition
To make a prediction, we choose a model,
- Constant Model:
- Prediction: fθ(x) = θ (Recipe to compute the prediction)
- Simple Linear Model:
- fθ(x) = θ1x + θ0 ( Two model weights)
The Constant Model
- Start simple: if constant model, how do we pick θ?
- Intuition: pick θ to be close to most of the values in data
Model Loss
- Use x to denote what we use to make predictions
- Use y to denote what we're trying to predict
- But both x and y come from a single sample
- Idea: Pick the θ that minimizes the average loss between y in our sample and model predictions.
Constant Model Loss

θ = sample mean is the best model parameter.

Pipeline:
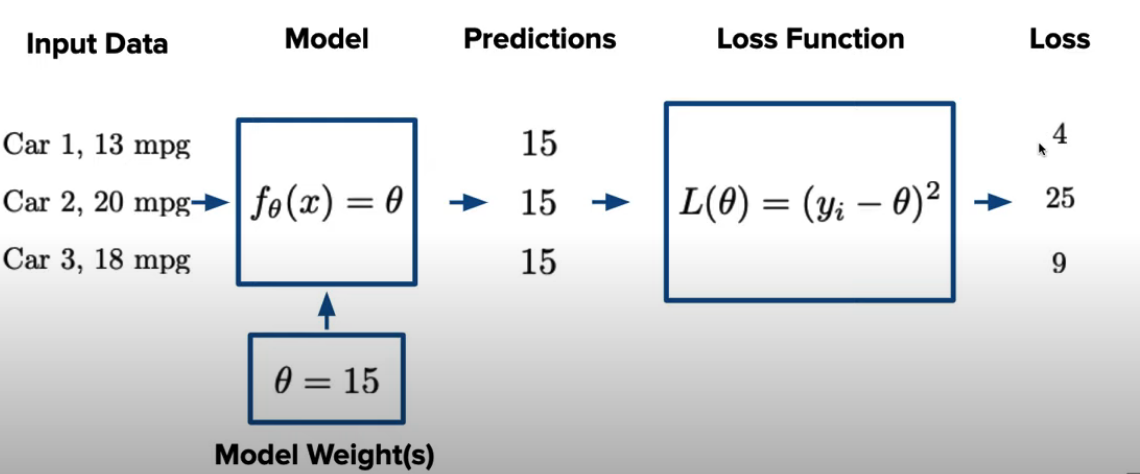
By finding weights that minimize loss. Minimizing sample loss approximates minimizing population loss.
Linear Model
Simple Linear Model

We can minimize the loss. We have two parameters.
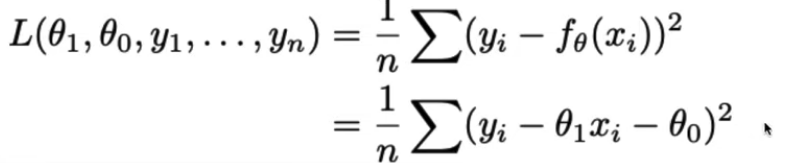
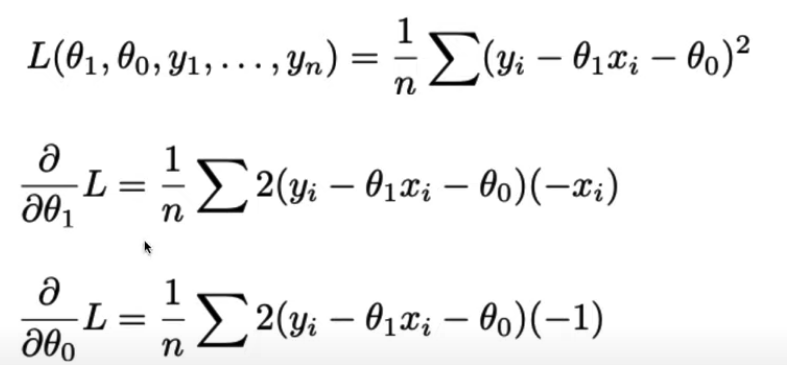
This ends up being a lot of algebra, so we will skip to the answer.
Multivariable linear model


Matrix Expression that computes the average MSE loss for all data points:
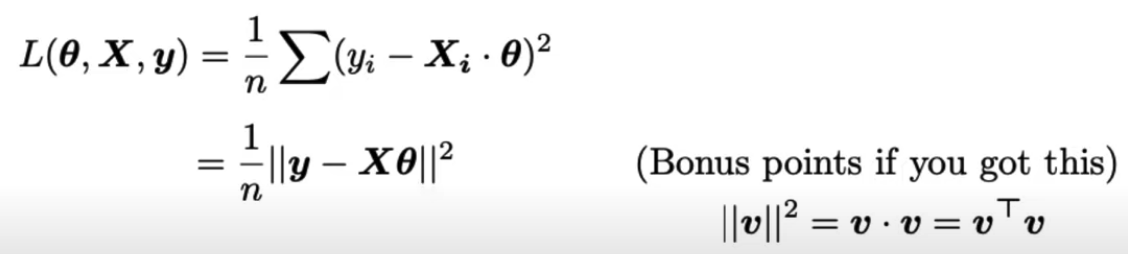
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Gradient Descent (0) | 2023.05.31 |
|---|---|
| SQL in Pandas Review (0) | 2023.05.30 |
| Text Fields Review (0) | 2023.05.30 |
| EDA Review (0) | 2023.05.30 |
| Data Cleaning Review (0) | 2023.05.28 |