
Schemas
Schema describes all relations and their attribute names & types.
- Granularity (what does one record in each table represent?)
- Primary and Foreign keys
- Representation
CREATE TABLE users(
id INTEGER PRIMARY KEY,
name TEXT
)
CREATE TABLE orders(
item TEXT PRIMARY KEY,
price NUMERIC,
name TEXT
)GROUP BY and HAVING
# SQL
SELECT max(name), legs, weight FROM animals
GROUP BY legs, weight
HAVING max(weight) < 100;# pandas
(animals.groupby(['legs', 'weight'])
.filter(lambda g: g['weight'].max() < 100)
.loc[:, ['name', 'legs', 'weight']]
.max())Cross Join
SELECT * FROM s, t;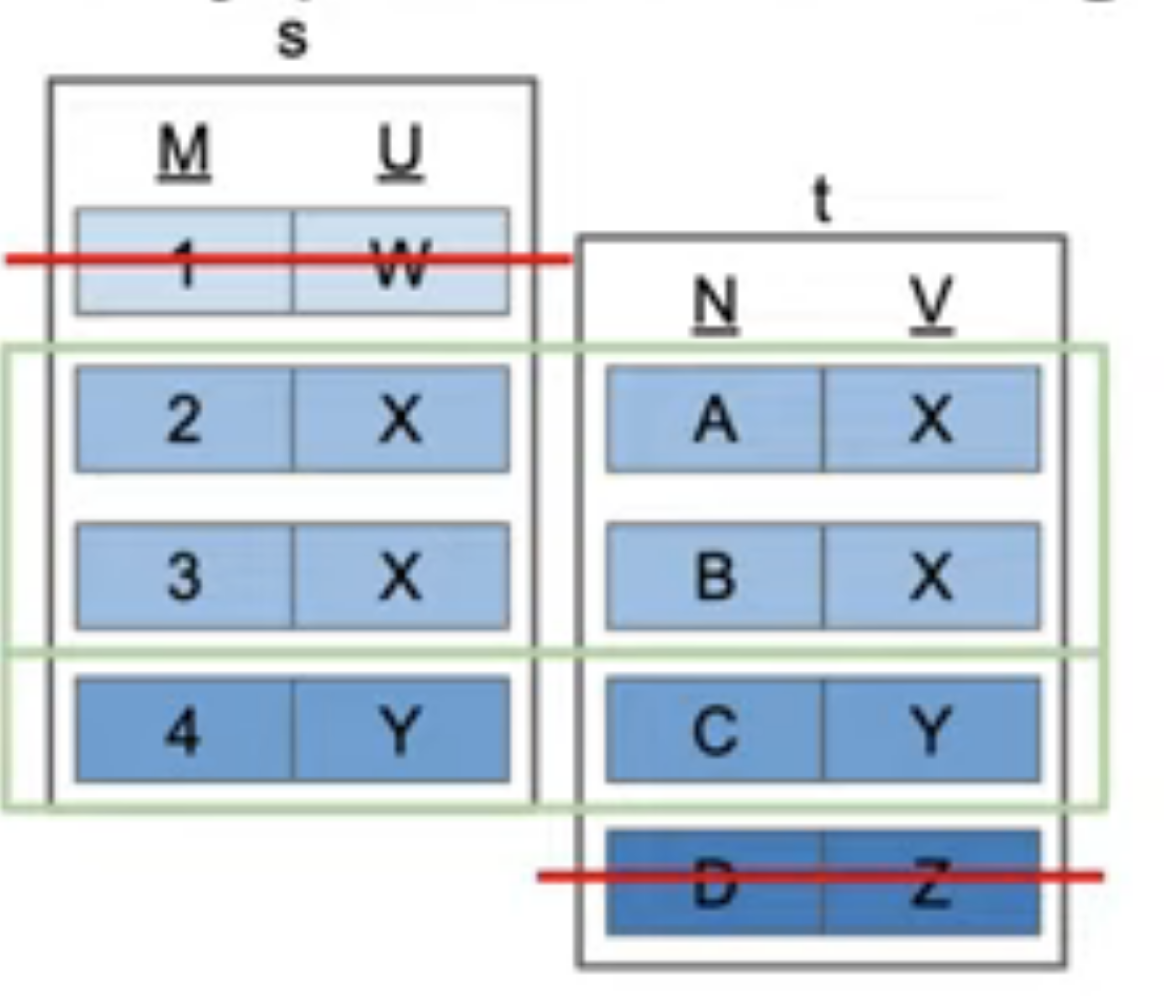
SELECT * FROM s JOIN t ON s.u = t.v;
SELECT * FROM s INNER JOIN t ON s.u = t.v;
SELECT * FROM s, t WHERE s.u = t.v;Result:
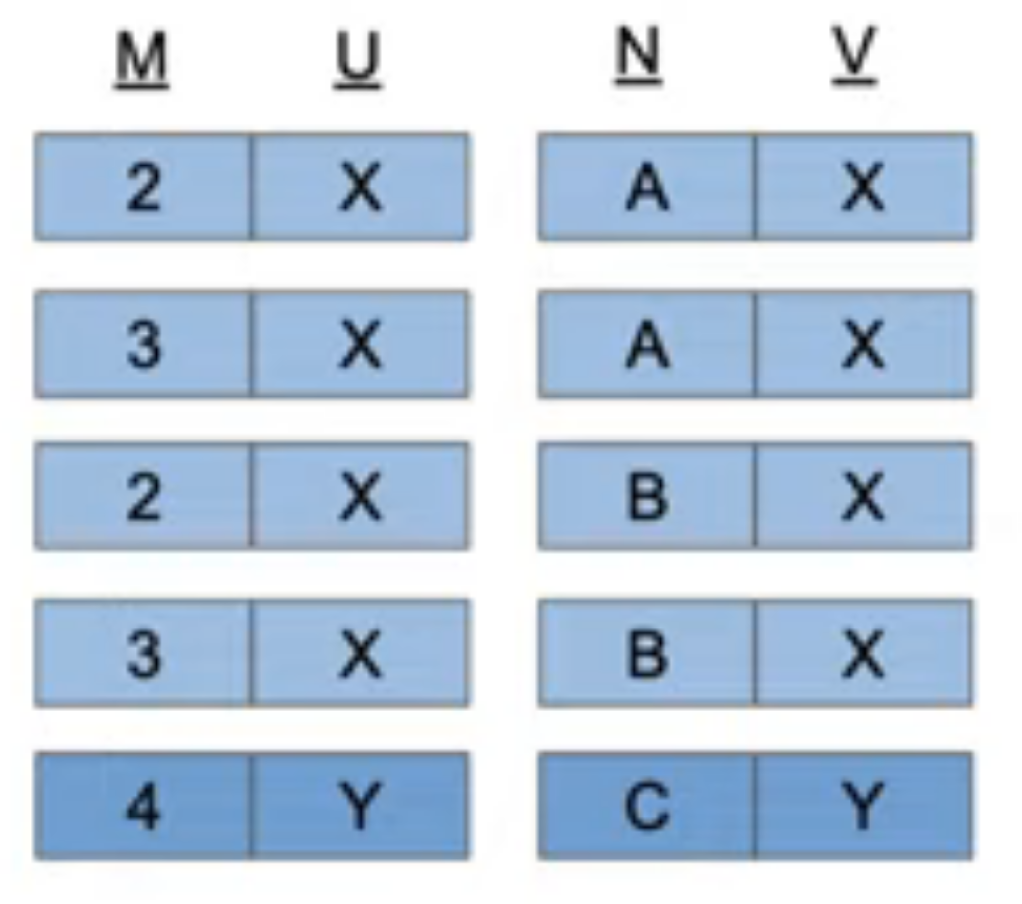
Left Outer Join
SELECT * FROM s LEFT JOIN t ON s.u = t.v;Result:

Sampling in SQL
SELECT * FROM t ORDER BY RANDOM() LIMIT 10;query = '''
SELECT *
FROM action
ORDER BY RANDOM()
LIMIT 5
'''
pd.read.sql(query, conn)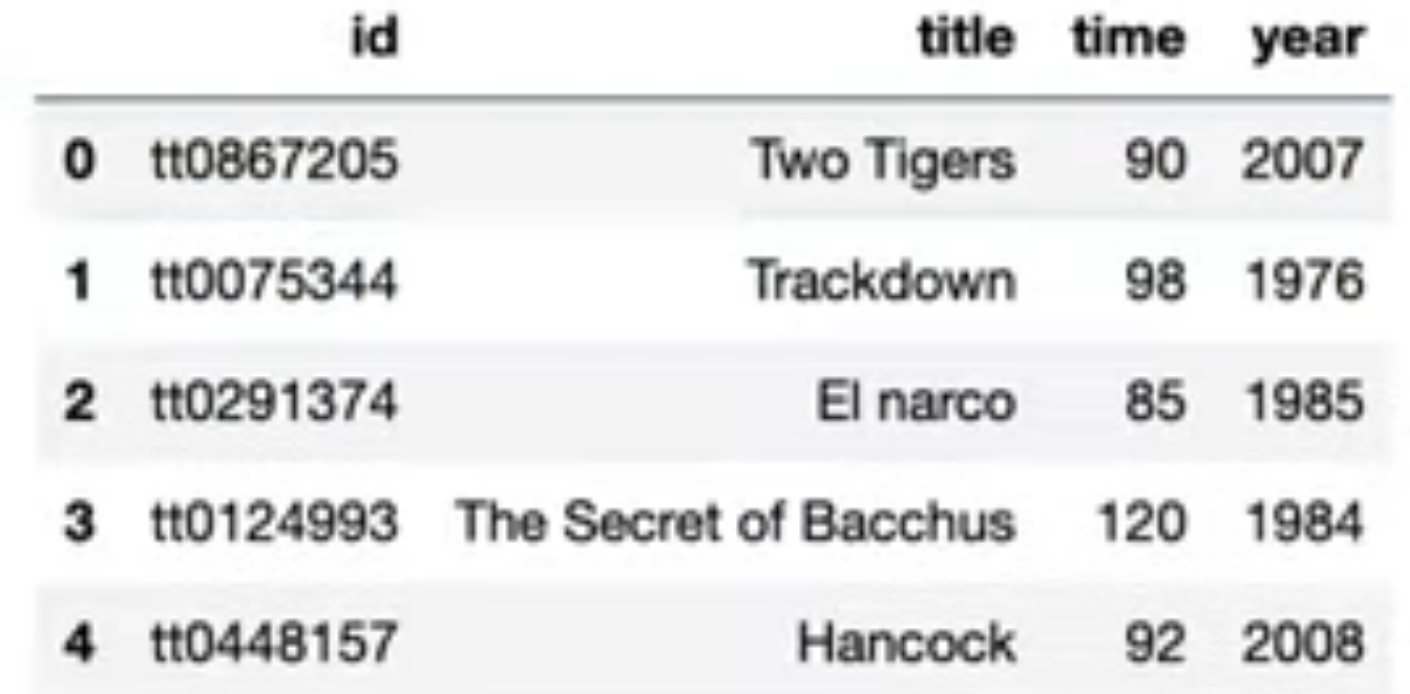
# How do I take a cluster sample of three years?
three_years = '''
SELECT year
FROM action
GROUP BY year
ORDER BY RANDOM()
LIMIT 3
'''
cluster_sample = f'''
SELECT *
FROM action
WHERE year IN ({three_years})
'''
pd.read_sql(f'''
SELECT year, COUNT(*)
FROM ({cluster_sample})
GROUP BY year
''', conn)avengers = '''
SELECT *
FROM action_ppl
WHERE title LIKE '%Avengers%'
'''
pd.read_sql(avengers. conn)
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Gradient Descent (0) | 2023.05.31 |
|---|---|
| Foundation of Machine Learning (0) | 2023.05.31 |
| Text Fields Review (0) | 2023.05.30 |
| EDA Review (0) | 2023.05.30 |
| Data Cleaning Review (0) | 2023.05.28 |
Schemas
Schema describes all relations and their attribute names & types.
- Granularity (what does one record in each table represent?)
- Primary and Foreign keys
- Representation
CREATE TABLE users(
id INTEGER PRIMARY KEY,
name TEXT
)
CREATE TABLE orders(
item TEXT PRIMARY KEY,
price NUMERIC,
name TEXT
)GROUP BY and HAVING
# SQL
SELECT max(name), legs, weight FROM animals
GROUP BY legs, weight
HAVING max(weight) < 100;# pandas
(animals.groupby(['legs', 'weight'])
.filter(lambda g: g['weight'].max() < 100)
.loc[:, ['name', 'legs', 'weight']]
.max())Cross Join
SELECT * FROM s, t;SELECT * FROM s JOIN t ON s.u = t.v;
SELECT * FROM s INNER JOIN t ON s.u = t.v;
SELECT * FROM s, t WHERE s.u = t.v;Result:
Left Outer Join
SELECT * FROM s LEFT JOIN t ON s.u = t.v;Result:
Sampling in SQL
SELECT * FROM t ORDER BY RANDOM() LIMIT 10;query = '''
SELECT *
FROM action
ORDER BY RANDOM()
LIMIT 5
'''
pd.read.sql(query, conn)# How do I take a cluster sample of three years?
three_years = '''
SELECT year
FROM action
GROUP BY year
ORDER BY RANDOM()
LIMIT 3
'''
cluster_sample = f'''
SELECT *
FROM action
WHERE year IN ({three_years})
'''
pd.read_sql(f'''
SELECT year, COUNT(*)
FROM ({cluster_sample})
GROUP BY year
''', conn)avengers = '''
SELECT *
FROM action_ppl
WHERE title LIKE '%Avengers%'
'''
pd.read_sql(avengers. conn)
'Computer Science 🌋 > Machine Learning🐼' 카테고리의 다른 글
| Gradient Descent (0) | 2023.05.31 |
|---|---|
| Foundation of Machine Learning (0) | 2023.05.31 |
| Text Fields Review (0) | 2023.05.30 |
| EDA Review (0) | 2023.05.30 |
| Data Cleaning Review (0) | 2023.05.28 |